
Co oznacza pojęcie “język naturalny”?
Język naturalny to język, którym komunikują się ludzie między sobą (np. język polski, język angielski itp.) – w przeciwieństwie, przykładowo, do języka programowania (np. Java, Python itp.), który służy do zlecania komputerowi zadań przez człowieka.
Czym jest przetwarzanie języka naturalnego?
NLP (ang. Natural Language Processing), czyli po polsku: przetwarzanie języka naturalnego, to operacje wykonywane przez komputer na wypowiedziach języka naturalnego. Operacje te mogą mieć na celu zrozumienie wypowiedzi, przełożenie jej na inny język czy też wygenerowanie nowej wypowiedzi.
Gdzie stosuje się NLP?
Przetwarzanie języka naturalnego stosowane jest w coraz szerszej palecie systemów komputerowych, realizujących takie zadania jak:
- tłumaczenie automatyczne,
- dialog między człowiekiem a komputerem,
- wyszukiwanie semantyczne,
- wydobywanie wiedzy z tekstu,
- klasyfikacja tekstów,
- analiza znaczenia tekstów,
- poprawa błędów językowych,
a także wiele innych.
W niniejszym wpisie na blogu omówię pokrótce wymienione powyżej zastosowania NLP.
Tłumaczenie automatyczne
Tłumaczenie automatyczne przeszło w ostatnich latach prawdziwą rewolucję, której efektem jest osiąganie znacznie lepszej jakości przekładów niż miało to miejsce jeszcze kilkanaście lat temu. Zainteresowanych historią tłumaczenia zachęcam do lektury odrębnego wpisu na powyższy temat, dostępnego na naszym blogu.
Tłumaczenie regułowe
Jeszcze na początku XX wieku najbardziej popularne były systemy tłumaczenia automatycznego oparte na słownikach oraz regułach opracowanych przez specjalistów. Na rynku polskim chętnie kupowano program Translatica firmy POLENG, który na podstawie reguł dokonywał analizy składniowej tłumaczonego tekstu, a w oparciu o jej wynik generował przetłumaczony dokument.
W pierwszej wersji systemu (w sumie powstało ich siedem) zdarzały się jednak “intrygujące” przypadki tłumaczenia, takie jak na przykład:
Zdanie polskie: Misiu zaraz państwu łapkę poda.
Tłumaczenie angielskie: The Teddy bear of epidemics will pass a trap to the State.
Chociaż rozbawienie wzbudza przypuszczalnie całe przytoczone powyżej tłumaczenie, najbardziej dziwi zapewne pojawienie się w nim frazy “of epidemics”. Otóż jest ona angielskim przekładem wyrazu “zaraz”, potraktowanego jako forma rzeczownika “zaraza” – odmienionego w liczbie mnogiej przez przypadki gramatyczne.
O tym, że kolejne wersje systemu radziły sobie z tłumaczeniem już znacznie lepiej, można przekonać się jeszcze dziś, korzystając z rozwiązania na stronie: www.translatica.pl.
Opracowanie, a następnie poprawianie, systemów regułowych wymaga jednak olbrzymiego nakładu pracy specjalistów. Z tego powodu metody regułowe były z czasem stopniowo wypierane przez inne metody tłumaczenia automatycznego.
Tłumaczenie statystyczne
Podstawy tłumaczenia statystycznego zostały opracowane w latach 90. XX wieku przez badaczy firmy IBM. Do powszechnego użytku systemy stosujące tę metodologię weszły w roku 2006, gdy uruchomiono serwis Google Translate.
Idea opisywanego sposobu tłumaczenia opiera się na pojęciu tzw. modelu zaszumionego (ang. noisy channel).
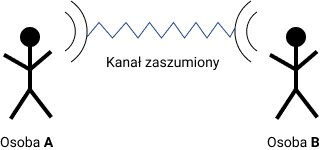
W modelu zaszumionym odbiorca (Osoba B) stara się odtworzyć oryginalny tekst nadawcy (Osoba A) w sytuacji, gdy został on zniekształcony podczas przesyłu. Sytuację taką możemy sobie wyobrazić na przykład w formie rozmowy przez telefon z osobą przebywającą na granicy zasięgu. Słysząc coś w rodzaju:
Co u ...bie? ...ak ...wie?
domyślamy się, że rozmówcy chodziło najpewniej o:
Co u Ciebie? Jak zdrowie?
a nie na przykład o:
Co u siebie? Tak w rowie? czy też
Co u niebie? Żak to wie?
Realizujemy bowiem w powyższej sytuacji proces składający się z dwóch kroków:
- tworzymy kilka hipotez wypowiedzi pasujących do tego, co usłyszeliśmy;
- wybieramy z nich tę najbardziej prawdopodobną.
W tłumaczeniu statystycznym jako kanał zaszumiony traktuje się proces translacji – “słyszymy” wypowiedź w jednym języku i staramy się odtworzyć, co było jej źródłem w innym języku. W tym celu:
- tworzymy kilka hipotez pasujących do tego, co usłyszeliśmy;
- wybieramy z nich najbardziej prawdopodobną.
Tłumaczenie neuronowe
Tłumaczenie neuronowe zaczęto stosować w roku 2014. Jego idea opiera się na zastosowaniu głębokich sieci neuronowych. W pierwszym kroku (zwanym kodowaniem) tekst przeznaczony do tłumaczenia przekształca się do postaci numerycznej (konkretnie: do wektora liczb rzeczywistych o długości od 300 do 500 elementów). W drugim kroku (zwanym dekodowaniem) wektor ten konwertowany jest do postaci tekstu w języku docelowym.
Z analizą porównawczą wyników tłumaczenia statystycznego i neuronowego można zapoznać się w artykule autorstwa Krzysztofa Jassema i Tomasza Dwojaka pt. Statistical versus neural machine translation – a case study for a medium size domain-specific bilingual corpus (2019).
Systemy dialogowe
Chatboty
Chatboty to systemy, które “rozmawiają” z użytkownikiem w języku naturalnym, starając się skierować jego zainteresowanie na określoną tematykę – najczęściej związaną z działalnością firmy udostępniającej tego typu rozwiązanie. Sposób działania chatbota jest z reguły dość prosty – system szuka w wypowiedziach użytkownika wyrazów kluczowych, a następnie kieruje go do stron internetowych z nimi związanych.
Istnieją też jednak chatboty służące głównie do celów rozrywkowych. Przykładem takiego rozwiązania może być system dialogowy dostępny na stronie: https://www.elbot.com/.
Systemy odpowiadania na pytania
Nieco bardziej zaawansowane koncepcyjnie są systemy odpowiadania na pytania. Dążą one do odkrycia potrzeby informacyjnej użytkownika zadającego pytanie w języku naturalnym, po czym wyszukują one odpowiedzi – bądź to we własnej bazie danych, bądź też na zewnętrznych stronach internetowych. Przykładem takiego rozwiązania może być system START (start.csail.mit.edu), opracowany na uniwersytecie MIT.
Wirtualni asystenci
Wirtualni asystenci to nasi nieodłączni przyjaciele – spełniający nasze zachcianki tu i teraz. Wystarczy powiedzieć “OK Google” i już nasz kolega czeka w gotowości, aby wyszukać dla nas informacje na dowolny interesujący nas temat. Pod względem popularności Asystent Google przebił już chyba legendarną Siri, która w roku 2011 została wprowadzona w smartfonach marki iPhone. Nieco z tyłu pozostaje w tej chwili Bixby – asystent instalowany w telefonach firmy Samsung – który bardzo chce nam pomagać w wielu życiowych sytuacjach – kłopot jednak w tym, że jego miłość nieczęsto spotyka się z odwzajemnieniem. Z kolei Alexa – wprowadzona przez firmę Amazon – niechętnie z nami podróżuje; woli przybrać postać małego głośniczka i poczekać na nas w domu. Tam jest już jednak niezastąpiona – przynajmniej jeśli idzie o domowe obowiązki.
Póki co nasi elektroniczni dżinowie nie zastąpią nam mimo wszystko kompana od piwa. Mają bowiem kłopot nie tylko z empatią, ale również z prowadzeniem naturalnej rozmowy. Działają niczym złota rybka – w myśl zasady: “Spełnię Twoje życzenie, ale pod warunkiem, że wypowiesz je jasno, wyraźnie i zwięźle. Zaraz potem się zmywam.”
Systemy prowadzenia dialogu
Trwają aktualnie prace nad budową systemów prowadzących dialog z użytkownikiem. Być może już niedługo zamiast wysłuchiwać na infolinii komunikatów typu: “Masz prawdziwe kłopoty – wciśnij siedem”, po wybraniu stosownego numeru usłyszymy automatycznego rozmówcę, który podyskutuje z nami jak “człowiek z człowiekiem”.
Jedną z testowanych w tym obszarze metod jest tzw. uczenie przez wzmacnianie. W tej technologii maszyna doskonali swoje działanie z wykorzystaniem systemu kar i nagród. Dzięki temu urządzenie może stać się na przykład ekspertem w grze Breakout (https://youtu.be/V1eYniJ0Rnk) w ciągu dosłownie kilku minut od momentu rozpoczęcia treningu.
Opanowanie sztuki prowadzenia dialogu okazuje się trudniejszym zadaniem. Problem ten ciekawie opisany został w pracy magisterskiej autorstwa Weroniki Sieińskiej zatytułowanej: Use of Reinforcement Learning in Dialogue Modeling (2019).
Wyszukiwanie semantyczne
Użytkownik wyszukiwarki internetowej oczekuje, że w reakcji na swoje zapytanie otrzyma odpowiedź, która spełniać będzie jego potrzeby – niekiedy sformułowane niejawnie. Wyszukiwanie semantyczne to technika selekcji informacji, która wychodzi naprzeciw następującym postulatom:
- opiera się na słowach kluczowych zapytania,
- odgaduje intencję pytającego,
- bierze pod uwagę kontekst zapytania.
I tak na przykład w odpowiedzi na polecenie:
Znajdź restaurację w pobliżu.
- wyszukiwarka semantyczna zidentyfikuje słowa kluczowe “restauracja” oraz “w pobliżu”, by z ich użyciem dokonać wyszukiwania informacji;
- postara się odgadnąć intencję pytającego, poszerzając zakres wyszukiwania również o informacje na temat pizzerii oraz barów;
- weźmie pod uwagę kontekst wypowiedzi – w tym wypadku lokalizację osoby pytającej – w celu wyfiltrowania wyłącznie placówek położonych w pobliżu aktualnego miejsca pobytu pytającego.
Wydobywanie a ekstrakcja informacji
Z zalewu tekstów dostępnych w Internecie nie zawsze łatwo jest za pomocą pojedynczego zapytania wydobyć dokładnie takie informacje, jakie by nas interesowały (nawet z wykorzystaniem wyszukiwania semantycznego). Poza tym w wielu przypadkach chcielibyśmy ograniczyć swe poszukiwania wyłącznie do określonych źródeł, zamiast przeczesywać całość zasobów dostępnych online.
Proces pozyskiwania dokumentów zawierających informacje związane ze sformułowanym pytaniem nazywamy wydobywaniem informacji (ang. information retrieval). Na przykład w odpowiedzi na prośbę o informacje dotyczące aktorów odgrywających rolę agenta Jamesa Bonda znajdujące się w zbiorze recenzji filmowych uzyskamy zestaw tych wszystkich recenzji, w których szukana informacja się pojawia.
Jeśli natomiast chcemy pozyskać informacje podane w określonym formacie, stosujemy proces nazywany ekstrakcją informacji (ang. information extraction). Na przykład w odpowiedzi na prośbę o informacje dotyczące aktorów odgrywających rolę agenta Jamesa Bonda możemy uzyskać tabelę zawierającą nazwiska stosownych aktorów oraz tytuły filmów, w których zagrali.
Ciekawe pomysły dotyczące metod ekstrakcji informacji można znaleźć w pracy magisterskiej autorstwa Dawida Jurkiewicza pt.: System ekstrakcji informacji o godzinach rozpoczęcia mszy świętych (2018).
Klasyfikacja tekstu
Klasyfikacja tekstu to automatyczny proces, którego celem jest przydzielenie każdego analizowanego dokumentu do pewnej klasy.
Klasyfikacja nadzorowana
W klasyfikacji nadzorowanej określa się z góry pewien zestaw klas, do których można przypisać każdy dokument. Często cytowanym przykładem tego typu jest detekcja spamu – dla każdego kolejnego maila system określa, czy zakwalifikować go jako spam, czy też dostarczyć go do skrzynki odbiorczej.
“Nadzór” ze strony człowieka polega na odpowiednim przygotowaniu danych uczących. Na przykład w opisywanym powyżej przypadku dla pewnego (najlepiej jak największego) zestawu maili człowiek decyduje, do której z klas każdy z nich przypisać. Z wykorzystaniem przygotowanych w ten sposób danych algorytm klasyfikacji uczy się naśladować działanie człowieka, by dla każdego nowego maila podjąć decyzję analogiczną do tej, jaką podejmował człowiek, oceniając dane uczące.
O przykładowej realizacji metody klasyfikacji nadzorowanej można przeczytać w pracy magisterskiej autorstwa Dawida Klimka zatytułowanej: Klasyfikacja funduszy inwestycyjnych z wykorzystaniem metod uczenia maszynowego (2017).
Klasyfikacja nienadzorowana
Przygotowanie danych uczących jest jednak procesem niezwykle pracochłonnym, dlatego w praktyce stosuje się często uczenie nienadzorowane. Nie wymaga ono klasyfikowania danych uczących przez człowieka. W zamian za to nie oczekuje się jednakże od algorytmu, że podzieli on dokumenty na klasy względem jakiejś określonej własności.
Najczęściej użytkownik wyznacza jedynie liczbę klas, na które chciałby podzielić zestaw dokumentów, a system działa w taki sposób, aby w każdej z nich znalazły się dokumenty do siebie podobne. Podobieństwo dokumentów można zdefiniować na bardzo różne sposoby – w najprostszym przypadku dokumenty uważamy za podobne, jeśli zawierają dużą liczbę wspólnych wyrazów.
Analiza wydźwięku
Analiza wydźwięku (ang. sentiment analysis) to rodzaj nadzorowanej klasyfikacji tekstu, w ramach której kategoryzuje się opinię wyrażoną w jego treści. Najczęściej stosuje się w tym przypadku podział na trzy klasy: pozytywną, negatywną oraz neutralną.
W niektórych zastosowaniach analizę wydźwięku odnosi się do określonych aspektów wypowiedzi. Na przykład w przypadku recenzji hotelu można skategoryzować opinię zawartą w analizowanym tekście ze względu takie aspekty jak: cena, lokalizacja, poziom obsługi czy jakość wyżywienia.
W pracy magisterskiej autorstwa Kingi Kramer zatytułowanej: Analiza wydźwięku komentarzy studentów do wykładu (2018) opisano na przykład eksperyment polegający na ocenie wydźwięku komentarzy studentów dotyczących wykładów autora niniejszego wpisu na blogu.
Korekta pisowni
Korekta pisowni to zadanie, w przypadku którego system informatyczny pełni rolę doradczą – wskazuje on potencjalne błędy w tekście, pozostawiając użytkownikowi ostateczną decyzję co do ich poprawy.
Korekta ortograficzna
W procesie tym zadaniem systemu jest wskazanie błędów ortograficznych, które powstały na skutek pomyłki typograficznej (użycia błędnego klawisza) lub nieznajomości ortografii ze strony autora tekstu. Błąd w pisowni może skutkować pojawieniem się wyrazu nieistniejącego w danym języku (np. mięso → mieso) i wtedy jest on łatwiejszy do wychwycenia. Może też jednak skutkować pojawieniem się wyrazu istniejącego w danym języku (np. mąki → maki), kiedy wychwycenie stosownego błędu jest o wiele trudniejszym zadaniem.
Jedną z popularnych metod wykrywania błędów pisowni jest wspomniana powyżej metoda kanału zaszumionego. Zakłada się, że błąd powstaje na skutek działania kanału zaszumionego, a zadaniem systemu jest wykrycie najbardziej prawdopodobnej intencji autora. Metoda ta opisana została w pracy magisterskiej autorstwa Tomasza Posiadały pt.: Probabilistyczne metody korekty pisowni (2017).
Korekta pozostałych błędów
Można wyróżnić całkiem sporą liczbę typów błędów popełnianych przez autorów posługujących się danym językiem jako obcym. Na przykład w korpusie NUCLE (https://www.comp.nus.edu.sg/~nlp/corpora.html), zawierającym teksty języka angielskiego autorstwa studentów z Singapuru, rozróżnia się 28 typów błędów, z których najczęściej popełniane to: niepoprawne użycie przedimka, zastosowanie niepoprawnej kolokacji wyrazowej, błąd interpunkcyjny, błąd dotyczący policzalności rzeczownika, niepoprawne użycie czasu gramatycznego czy zastosowanie nieprawidłowego przyimka.
Współczesne systemy są w stanie całkiem dobrze radzić sobie z tego typu błędami. Jednym ze skuteczniejszych rozwiązań jest zastosowanie neuronowego modelu translacji na potrzeby “przetłumaczenia” tekstu z języka niepoprawnego na poprawny. Więcej informacji na temat współczesnych metod korekty gramatycznej znaleźć można w pracy doktorskiej autorstwa Romana Grundkiewicza zatytułowanej: Algorithms for automatic verification of grammatical correctness (2018).
Inne zastosowania
Zastosowań NLP jest jednak znacznie więcej niż te opisane powyżej. Pokrótce omówię tutaj jeszcze tylko kilka z nich.
Streszczanie dokumentów
Celem zadania jest dokonanie automatycznego streszczenia dokumentu – najczęściej poprzez selekcję tych jego zdań czy fragmentów tekstu, które niosą z sobą najwięcej informacji. Przykładowa realizacja takiego zadania opisana została w pracy magisterskiej autorstwa Łukasza Pawluczuka pt.: Automatic Summarization of Polish News Articles by Sentence Selection (2015).
Predykcja trendów
Na podstawie informacji zawartych w tekstach system uczenia maszynowego może przewidywać trendy w określonych mechanizmach gospodarki. W pracy magisterskiej autorstwa Marcina Kani zatytułowanej: System wspomagania decyzji o inwestowaniu na polskiej giełdzie w oparciu o komunikaty giełdowe (2014) opisano system przewidywania kursów akcji spółek notowanych na Giełdzie Papierów Wartościowych w Warszawie na podstawie komunikatów prasowych publikowanych przez powyższe podmioty.
Automatyczny sufler
Automatyczny sufler podsłuchuje na bieżąco rozmowę ludzką. Ilekroć usłyszy frazę wskazującą na niepewność co do znaczenia lub brak znajomości jakiegoś terminu (np. “Zastanawiam się…” “Co to jest…?”), wkracza do akcji, oferując wyczerpujące informacje na niejasny temat. Brrr…
Ghost writer
Piszesz właśnie podanie i brakuje Ci słów lub pomysłu na skuteczną autoreklamę? Pomoże Ci w tym przypadku automatyczny “ghost writer”, czyli Twój osobisty asystent-redaktor. Rozwiązania tego typu oferuje na przykład firma textio (https://textio.com/).
A teraz zgadnijcie: Kto / Co był(o) autorem niniejszego wpisu na blogu?
Autor:
prof. dr hab.
Krzysztof Jassem