NLP w Linuxie czyli „Jak zostać królem w erze oszczędności?”
Przyjęło się uważać, że przetwarzanie dokumentów tekstowych wymaga znajomości języka programowania wysokiego poziomu. Kilkanaście lat temu “wypadało” dobrze znać język Perl, natomiast dziś specjalista w tej dziedzinie “absolutnie musi” mieć opanowany język Python. Czy naprawdę jest to niezbędne?
W niniejszym wpisie pokażę, że nawet całkiem zaawansowane zadania związane z przetwarzaniem tekstu można łatwo i szybko wykonać bez znajomości ani jednego polecenia jakiegokolwiek języka programowania.
Nie tak dawno temu, wcale nie tak daleko stąd, rozciągała się kraina mlekiem i miodem płynąca, którą rządził mądry i sprawiedliwy król. Władca ów miał trzy piękne i roztropne córki. Każda z nich posiadała wszelkie cnoty potrzebne, by kontynuować dzieło ojca przez następne pokolenia.
Jednak prastare prawo, sięgające tysiącleci, głosiło, iż berło królewskie może przejąć jedynie męski następca. Toteż po rękę najstarszej królewny ustawiła się długa kolejka śmiałków.
Król, przewidując nadchodzące trudne czasy, rzekł do siebie:
"Królem zostanie ten, kto wykona przygotowane przeze mnie zadanie, zużywając najmniej cennych zasobów."
Zmiany klimatyczne kurczyły bowiem zapasy energii, a ludzie przywykli do wygód i luksusu.
Lista frekwencyjna wyrazów
Wkrótce w królewskim biuletynie ukazało się obwieszczenie:
"W najnowszych księgach królestwa pojawiły się dziwne wyrazy pochodzące z odległych krain: influencer, selfie, hashtag, anime, barista, tapas. Nie wiadomo, które z nich można uznać za godne stosowania. Król potrzebuje listy częstości ich występowania w księgach królestwa. Jako dopuszczalne uznane będą te wyrazy, które powtórzyły się co najmniej milion razy!
Zadanie to posłuży zarazem do wyłonienia najlepszego kandydata na królewskiego następcę. Mężem najstarszej córki króla i zarazem następcą tronu zostanie ten, kto z najmniejszym zużyciem zasobów sporządzi taką listę."
Zapytanie do modelu języka
Pierwszy śmiałek przedstawił proste rozwiązanie:
– Wasza Wysokość, może to uczynić słynny model języka, który zna wiedzę z niezliczonych ksiąg. Wypowiadamy zaklęcie Lista frekwencyjna ksiąg królestwa i otrzymujemy wynik – listę częstości wystąpień wszystkich wyrazów pojawiających się w naszych księgach. O, proszę, oto wynik – okazuje się, że każdy z tych „dziwnych” wyrazów wystąpił w księgach królestwa ponad milion razy. Najczęściej – anime (12 milionów), najrzadziej – tapas (1,5 miliona). Dla porównania słowo król pojawiło się 25 milionów razy.
Król pokiwał głową:
– Ciekawe. Widzę, że obce wyrazy zagościły już na dobre w naszym języku. Wyjaśnij mi, jak działa ów model.
– W modelu języka znajduje się wiedza z bardzo wielu ksiąg z całego świata. Niektóre z nich zawierają informacje o tym, jak uzyskiwać informacje za pomocą tzw. programów komputerowych. Model języka przetłumaczył nasze zapytanie do postaci programu komputerowego, który ułożył listę frekwencyjną.
Król zmarszczył brwi:
– Ależ to ogrom energii: zapamiętać tyle ksiąg i jeszcze szukać w nich rozwiązania. Czy to na pewno oszczędne?
Program w języku Python
Drugi śmiałek stanął przed tronem:
- Napisałem program, który można uruchomić nawet na komputerze o małej mocy. Jest on zwięzły, a przeprowadzone zgodnie z nim obliczenia są niezwykle proste:
words = open('ksiegi').read().split()
freq = {}
for w in words: freq[w] = freq.get(w, 0) + 1
for word in sorted(freq): print(word, freq[word])
– Program składa się zaledwie z czterech linii – oznajmił śmiałek, prostując się dumnie. – Pierwsza z nich odczytuje tekst z ksiąg i dzieli go na wyrazy.
W drugim i trzecim wierszu tworzony jest, początkowo pusty, zbiór par; pierwszym elementem każdej pary jest wyraz, a drugim — jego liczba wystąpień w księgach – z każdym kolejno napotkanym wyrazem liczba jego wystąpień zwiększa się o 1.
W ostatnim wierszu wyświetlana jest informacja o liczności wszystkich wyrazów w księgach, przy czym lista wyrazów jest posortowana, czyli ułożona w kolejności alfabetycznej.
Król zmarszczył brwi i rzekł:
– Z tego, co mi wiadomo, komputery rozumieją jedynie ciągi zer i jedynek. Jakim cudem potrafią zrozumieć taki kod?
Śmiałek odparł:
– Kod napisany przeze mnie tłumaczony jest na ciąg zer i jedynek za pomocą specjalnego tłumacza, który zwie się interpreterem. Ów interpreter został wcześniej opracowany przez mistrzów sztuki komputerowej.
Król zamyślił się, podpierając brodę dłonią.
– To chyba bardziej oszczędne rozwiązanie niż ów potężny model języka – mruknął. – Ale czy można by wykonać to zadanie bez udziału owego tłumacza?
Na to pytanie śmiałek nie potrafił odpowiedzieć. Milczał, spuszczając wzrok.
Polecenia powłoki Bash
Trzeci śmiałek uśmiechnął się pewnie:
— Wasza Królewska Mość — przemówił — nam, ludziom, zawsze potrzebny będzie pośrednik w rozmowie z komputerami. Żaden śmiertelnik nie włada przecież językiem zer i jedynek.
— Ja jednak poznałem prastary język, który me tę cudowną zaletę, że tłumaczenie jego słów na mowę maszyn jest o wiele sprawniejsze. W tym starożytnym języku całe nasze zadanie da się zamknąć w jednej linijce:
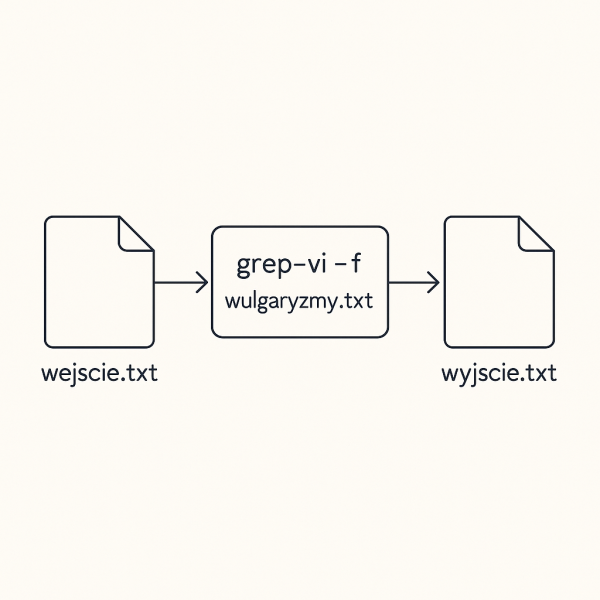
tr -cs '[:alnum:]' '\n' < księgi | sort | uniq -c
– Ten napis wygląda jak czarna magia! – zawołał król, marszcząc brwi. – Ileż czasu musiałbym poświęcić, by go zrozumieć?!
Potoki w powłoce Bash
Śmiałek ukłonił się z szacunkiem i rzekł łagodnie:
– Wystarczy odrobina cierpliwości, Wasza Wysokość. Jeżeli pozwolicie, zacznę od pytania: W jaki sposób możemy wprowadzać dane — na przykład teksty z ksiąg — do komputera?
Król zamyślił się i odpowiedział:
– Na przykład z klawiatury albo poprzez pobranie ich z ksiąg zapisanych na komputerze.
– Doskonale, Wasza Wysokość! Ten pierwszy przypadek uznaje się za standardowy. Gdy, dajmy na to, wydajemy komputerowi polecenie sort, zakłada on, że za chwilę wprowadzimy z klawiatury dane, które należy uporządkować (posortować).
Lecz jeśli pragniemy posortować dane pochodzące z „ksiąg zapisanych na komputerze” — czyli, mówiąc bardziej uczenie, z pliku tekstowego — stosujemy znak strzałki <.
Na przykład polecenie:
sort < księgi
oznacza, że dane z pliku o nazwie księgi mają być przekazane do polecenia sort, które uporządkuje ich zawartość.
Król kiwnął głową, lecz zaraz zapytał:
– A cóż oznaczają te pionowe kreski w Twoim magicznym napisie?
Śmiałek z uśmiechem odparł:
– Kreska taka jest symbolem potoku, którym dane płyną do dalszego przetwarzania. Na przykład zapis:
sort | uniq
oznacza, że posortowane dane mają popłynąć do polecenia uniq (pochodzące od wyrazu unique), które usunie powtarzające się linie.
Zaczynam rozumieć. Ale w tym napisie jest jeszcze sporo niewiadomych. Zacznijmy zatem od początku naszej komendy.
Śmiałek skinął głową i rzekł:
– Polecenie tr (pochodzące od wyrazu translate) służy do zamiany znaków w tekście. Na przykład:
tr 'A' 'a'
zamienia w tekście wszystkie duże litery A na małe litery a.
Opcje poleceń w powłoce Bash
Można też zastosować odwrócenie zastępowanych znaków poprzez rozszerzenia polecenia opcją -c (complement). Na przykład napis:
tr -c 'A' '_'
oznacza, że wszystkie znaki, które nie są literą A, zostaną zastąpione podkreśleniem.
Król słuchał uważnie. Śmiałek mówił dalej:
– Jeszcze bardziej użyteczna jest komenda:
tr -c '[:alnum:]' '\n'
która zamienia wszystkie znaki niebędące literami ani cyframi (litery i cyfry oznaczane są łącznie jako [:alnum:]), jak spacje, przecinki i inne znaki interpunkcyjne — na znak nowej linii (oznaczany jako \n).
W efekcie zastosowaia tej komendy przykładowe zdanie:
król ma berło, a królowa ma koronę
zostaje przekształcone w taki oto „pionowy” zapis, dzięki znakom końca linii, które zastąpiły znaki niebędące literami i podzieliły tekst na linie.
król
ma
berło
a
królowa
ma
koronę
Król przyjrzał się wynikowi i zapytał:
– A skąd się wzięła pusta linia między wyrazami berło i a?
– Spacja została zamieniona na jeden znak nowej linii, a przecinek na drugi. I właśnie dlatego w proponowanej przeze mnie komendzie:
tr -cs '[:alnum:]' '\n'
użyłem dodatkowej opcji -s(squeeze), która ściska wszystkie powtarzające się znaki do jednego — w tym przypadku kilka kolejnych znaków nowej linii zostaje zastąpionych jednym.
Król pokiwał głową z uznaniem.
– Czyli wczytujemy plik zawierający księgi i przetwarzamy go tak, że w każdej linii znajduje się jeden kolejny wyraz. Co dzieje się dalej?
Śmiałek wyjaśnił:
– Potok danych płynie do polecenia sortowania (sort), które porządkuje wyrazy alfabetycznie. Następnie dane przekazywane są do polecenia uniq, które usuwa duplikujące się wiersze (czyli w sytuacji gdy w kolejnych wersjach występują takie same wyrazy, wiele ich wystąpień zostanie zastąpionych jednym).
A ponieważ dodatkowo używamy opcji -c (count), dla każdego wyrazu zostaje policzona liczba wystąpień.
Wynik wygląda zatem następująco:
a 1
berło 1
koronę 1
król 1
królowa 1
ma 2
Król spojrzał z zaciekawieniem:
– I co się dalej dzieje z tą listą?
Śmiałek odrzekł:
– W naszym przypadku wynik jest traktowany standardowo, czyli wyświetlany na ekranie.
Jednakże, gdybyśmy chcieli go zachować w księgach, moglibyśmy przesłać go do pliku o nazwie np. lista, używając znaku strzałki >:
tr -cs '[:alnum:]' '\n' < ksiegi | sort | uniq -c > lista
Pórównanie przetwarzania w Pythonie i powłoce Bash
Król jeszcze nie był do końca przekonany i zmarszczył brwi.
— Powiedz mi, młodzieńcze — rzekł — dlaczego uważasz, że twoje metody zużywają mniej mocy niż pomysły twego poprzednika?
Śmiałek skłonił się z szacunkiem i odparł:
— Wasza Królewska Mość, pozwólcie, że opowiem to prostym przykładem. Wyobraźcie sobie, że proszę Was o powtórzenie dziesięciocyfrowego kodu. Moglibyście powtarzać go cyfra po cyfrze lub próbować zapamiętać cały kod naraz. Które zadanie wymagałoby więcej wysiłku i zużycia mocy umysłu?
Król zamyślił się na moment i odrzekł:
— Oczywiście, zapamiętanie wszystkich dziesięciu cyfr naraz.
— Właśnie tak! — zawołał młodzieniec – Mój sposób bierze to pod uwagę! Nie gromadzę wszystkich wyrazów w pamięci komputera, lecz przetwarzam je jedno po drugim. Natomiast metody mego poprzednika najpierw zapamiętywały wszystkie wyrazy, a dopiero potem nad nimi pracowały, co wymagało ogromnych ilości pamięci i czasu.
— Warto znać prastary język — kontynuował młodzieniec — Dzięki niemu jesteśmy w stanie bezpośrednio zarządzać pracą komputera, dbając o oszczędność zużywanych zasobów.
I tak, niedługo potem w królestwie odbyło się huczne wesele.
Zgadnijcie, kto został szczęśliwym wybrańcem?