
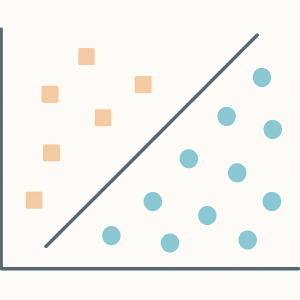
Klasyfikacja a regresja
W jednym z wcześniejszych wpisów na blogu omówiłem zadanie klasyfikacji, które polega na automatycznym określaniu, do jakiej klasy należy badany obiekt. System klasyfikacji przypisuje badanemu obiektowi etykietę klasy, przy czym liczba możliwych etykiet jest z góry określona.
W zadaniu regresji system uczenia maszynowego przydziela natomiast badanemu obiektowi pewną wartość liczbową z nieskończonego spektrum możliwości. Weźmy jako przykład komplet recenzji pewnej restauracji w serwisie TripAdvisor. Oto wybrana recenzja ze wspomnianego zbioru:
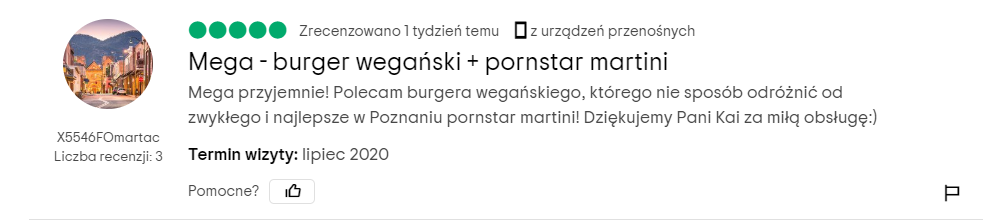
Dla takiego zestawu danych zdefiniować można co najmniej kilka różnych zadań klasyfikacji – na przykład:
- przypisz recenzję do jednej z trzech klas według kryterium nastawienia autora: pozytywne, negatywne lub neutralne;
- określ lokalizację opisywanej restauracji, mając do wyboru szesnaście polskich województw;
- określ typ kuchni serwowanej w opisywanej restauracji (np. polska, europejska, azjatycka itp.).
Przykładowe zadanie regresji dla takiego zestawu recenzji może mieć natomiast następującą formę:
Na podstawie recenzji określ jakość opisywanej w niej usługi w postaci liczby rzeczywistej z przedziału od 0 do 5.
Wartością obliczoną przez system regresji na podstawie recenzji może być na przykład liczba 3,45, przy czym oczekujemy, że wartość zwrócona przez system będzie adekwatna do opinii wyrażonej w recenzji: jeśli opinia ta jest bardzo pozytywna, będzie ona zbliżona do liczby 5, a jeśli zdecydowanie negatywna – będzie ona bliska zeru.
Do czego może przydać się regresja?
Regresja dostarcza bardziej precyzyjnych informacji niż klasyfikacja. Dzięki niej możemy na przykład śledzić na bieżąco postępy, jakie czyni obserwowana restauracja w zakresie jakości oferowanych usług, poprzez porównywanie wartości opinii na jej temat na przestrzeni czasu. System regresji może też z wykorzystaniem tego typu analiz przewidywać przyszłe wartości indeksów giełdowych – a tutaj już dokładność, nawet do wielu miejsc po przecinku, staje się kluczowa.
Cechy obiektu
Metoda regresji umożliwia obliczenie wartości przewidywanej na podstawie cech obiektu. W uczeniu maszynowym cechą obiektu nazywamy taką jego własność, której wartość można określić liczbowo. Cechą recenzji może być na przykład liczba zawartych w niej wyrazów o nacechowaniu pozytywnym lub liczba zawartych w niej wyrazów o wydźwięku negatywnym. Opracowując system komputerowy wykorzystujący metodę regresji, inżynier systemu sam określa zestaw cech, które będą brane pod uwagę.
Regresja liniowa
Metoda regresji liniowej zakłada, że przewidywaną wartość można wyliczyć z zastosowaniem funkcji liniowej wartości cech. Możemy na przykład przyjąć założenie, że wartość danej opinii jest wprost proporcjonalna do liczby zawartych w niej wyrazów o nacechowaniu pozytywnym, co wyraża się wzorem:
WARTOŚĆ = Ⲁ x LICZBA WYRAZÓW POZYTYWNYCH
gdzie Ⲁ jest liczbą dodatnią.
Możemy dodatkowo przyjąć, że przewidywana wartość jest odwrotnie proporcjonalna do liczby wyrazów o wydźwięku negatywnym:
WARTOŚĆ = Ⲁ x LICZBA WYRAZÓW POZYTYWNYCH
+ 𝛽 x LICZBA WYRAZÓW NEGATYWNYCH
gdzie 𝛽 jest liczbą ujemną.
Jeśli zdefiniowana przez nas w ten sposób funkcja zwraca przykładowo wartości w zakresie od -1 do 4, a pożądane jest, aby wyniki mieściły się w zakresie od 0 do 5, możemy “przesunąć” zakres zwracanych wartości poprzez dodanie “parametru przesunięcia”:
WARTOŚĆ = Ⲁ x LICZBA WYRAZÓW POZYTYWNYCH
+ 𝛽 x LICZBA WYRAZÓW NEGATYWNYCH
+ 𝛾
Zadanie regresji liniowej polega w tym wypadku na wyznaczeniu takich wartości współczynników Ⲁ, 𝛽 oraz 𝛾, aby wartość wyliczana powyższym wzorem była zgodna z oczekiwaniami.
Kiedy mówimy, że wyniki regresji są zgodne z oczekiwaniami?
Jeśli regresję stosujemy do oceny obiektów (np.: Jakie jest nastawienie autora recenzji do recenzowanej usługi w skali od 0 do 5?), metoda działa zgodnie z oczekiwaniami, gdy zwracane przez nią wartości w dużym stopniu pokrywają się z intuicją ludzką.
Jeśli metodę regresji stosujemy do prognozowania (np.: Jakie będą w następnym miesiącu wartości indeksów giełdowych? Jaka będzie wartość sprzedaży podręczników we wrześniu?), jej wyniki są zgodne z oczekiwaniami, jeżeli prognozy różnią się od rzeczywistości o niewielką wartość (co można sprawdzić post factum).
Jak wyznacza się współczynniki regresji?
Współczynniki regresji obliczane są na podstawie danych uczących, czyli zestawu obiektów, dla których znane są zarówno wartości ich cech, jak i wartości przewidywane. Na przykład daną uczącą może być recenzja restauracji zaprezentowana na początku tego wpisu. Zawiera ona 5 wyrazów pozytywnych (mega, przyjemnie, najlepsze, dziękujemy, miłą) oraz jedno słowo negatywne (nie), a ocena punktowa przydzielona przez autora opinii recenzowanemu lokalowi (będąca w tym wypadku wartością przewidywaną) to liczba 5 (przy recenzji widoczne jest pięć zielonych kropek). Gdybyśmy mieli wyznaczyć współczynniki regresji na bazie wyłącznie tego jednego przykładu, mogłyby mieć one następujące wartości:
Ⲁ = 1
𝛽 = -1
𝛾 = 1
W takim przypadku wartość przewidywana recenzji wyliczona z podanego wcześniej wzoru powyżej wyniosłaby:
WARTOŚĆ = 1 x 5 + (-1) x 1 + 1 = 5
Wartość wyliczona ze wzoru na regresję liniową byłaby zatem identyczna z oceną punktową recenzji ze zbioru uczącego. Brawo!
Załóżmy jednak, że inna opinia ze zbioru uczącego – również opatrzona pięcioma punktami – ma następującą treść:
Super restauracja! Nie mogę się doczekać, kiedy znowu do niej pójdę!
Zastosowanie tych samych wartości współczynników Ⲁ, 𝛽 oraz 𝛾, gdy liczba wyrazów pozytywnych (Super) i negatywnych (nie) wynosi po 1, obliczona według podanego wcześniej wzoru wynosi:
WARTOŚĆ = 1 x 1 + (-1) x 1 + 1 = 1
W tym przypadku wartość wyliczona ze wzoru na regresję liniową różni się zatem od oceny samego użytkownika aż o 4 punkty! Wprowadzenie drugiej danej do zbioru uczącego pociąga więc za sobą konieczność zmiany współczynników – na przykład na poniższe:
Ⲁ = 0,5
𝛽 = -0,5
𝛾 = 4
Po powyższej modyfikacji współczynników wartość funkcji oceny dla omawianej wcześniej pierwszej danej uczącej wynosi 6 (czyli o 1 za dużo), podczas gdy dla analizowanej powyżej drugiej danej uczącej wynosi ona 4 (a zatem o jeden za mało). Dla obu danych łącznie różnica między wartością funkcji a wartością rzeczywistą wynosi jednak zaledwie 2 – podczas gdy przy poprzednim doborze wartości współczynników wynosiła ona 4.
Funkcja kosztu
Współczynniki regresji wyznacza się w taki sposób, aby suma różnic między wynikiem funkcji liniowej a wartością rzeczywistą łącznie dla wszystkich danych uczących była jak najmniejsza. Taką łączną sumę różnic między wynikami funkcji liniowej a wartościami rzeczywistymi określa się mianem funkcji kosztu.
Posługując się językiem matematycznym: celem metody regresji jest znalezienie takich wartości współczynników regresji, dla których funkcja kosztu osiąga swoje minimum.
Metoda gradientu prostego
Metoda gradientu prostego służy do znalezienia minimum funkcji, czyli wartości argumentu (argumentów), dla którego (których) funkcja przyjmuje najmniejszą wartość. Wyjaśnijmy jej istotę, posługując się przykładem, w którym funkcja ma tylko jeden argument.
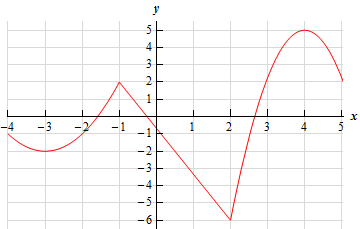
Jak widać na powyższym wykresie, analizowana funkcja przyjmuje najmniejszą wartość (równą -6) dla wartości argumentu x = 2. Wartość 2 stanowi zatem minimum tej funkcji. Na potrzeby zobrazowania metody gradientu posłużymy się Opowieścią o pustym baku.
Opowieść o pustym baku

Wyobraźmy sobie, że wybraliśmy się na samochodową wycieczkę w góry. W połowie zbocza pokonywanego wzniesienia auto nagle zatrzymało się – z najbardziej prozaicznego powodu, jaki mógłby przyjść nam do głowy: w jego baku zabrakło po prostu paliwa. Trzeba będzie zatem dotrzeć teraz piechotą na najbliższą stację benzynową.
Nie znamy co prawda jej lokalizacji, lecz jedno wiemy na pewno: stacja znajduje się w najniższym punkcie naszej drogi. W którą stronę zatem się udać? Rozglądamy się dokoła: w jedną stronę droga prowadzi do góry, w drugą zaś – w dół. Robimy więc krok w dół, po czym powtarzamy powyższą procedurę.
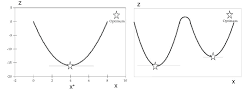
Czy w ten sposób na pewno dotrzemy do poszukiwanej stacji paliw? Jeśli przekrój drogi wygląda tak jak na lewym z powyższych rysunków, na pewno nam się to uda. Jeśli jednak przekrój ten ma kształt taki jak na rysunku po prawej stronie – już niekoniecznie.
Metoda gradientu prostego działa analogicznie do Opowieści o pustym baku:
- Zacznij w dowolnym miejscu (np. dla zerowej wartości argumentu), po czym powtarzaj kroki 2) i 3).
- Jeśli funkcja jest w danym miejscu malejąca (tzn. jej wartość maleje, gdy wartość argumentu rośnie), przemieść się po wykresie funkcji w prawo.
- W przeciwnym wypadku (tzn. jeśli wartość funkcji maleje, gdy wartość argumentu maleje), przemieść się po wykresie funkcji w lewo.
Poruszaj się w ten sposób do momentu, kiedy funkcja nie maleje w żadną ze stron. Jesteś na miejscu!
Funkcje wypukłe
Taki algorytm skutecznie znajduje minimum dla wszystkich funkcji, których wykres przypomina rysunek po lewej stronie – czyli takich, które mają one dokładnie jeden “dołek”. Funkcje takie nazywane są funkcjami wypukłymi. Algorytm ten może jednak nie zadziałać poprawnie w przypadku funkcji takich jak ta, której wykres przedstawiono na rysunku po stronie prawej.
Tak się na szczęście składa, że interesująca nas funkcja kosztu jest funkcją wypukłą. Metoda gradientu prostego działa zatem na potrzeby tej funkcji idealnie!
Regresja logistyczna
Wyniki zwracane przez regresję liniową nie zawsze niestety w pełni satysfakcjonują odbiorcę. Owszem, gdy oczekujemy od systemu prognozy temperatury, cieszy nas wynik w skali Celsjusza. Kiedy potrzebna jest nam prognoza giełdowej wyceny akcji, jesteśmy zadowoleni, gdy system zwraca nam wartość wyrażoną w złotówkach. Wartość oceny wyrażonej w recenzji podana jako 3,45 pozostaje jednak dla nas niejasna, o ile nie jest nam znana skala, jaką operujemy. Być może w takim przypadku lepiej byłoby uzyskać wynik w skali procentowej (np. 69%)? Gdybyśmy natomiast chcieli przewidzieć szanse Szymona Hołowni w wyborach na urząd prezydenta w roku 2025, to już na pewno oczekiwalibyśmy wyniku wyrażonego w procentach, a nie liczby z nieznanego nam bliżej zakresu.
Funkcja logistyczna
Regresja logistyczna umożliwia przeliczenie wyniku uzyskanego w efekcie zastosowania regresji liniowej w taki sposób, aby jego wartość zawierała się w przedziale od 0 do 1. W tym celu na wynik uzyskany z zastosowaniem regresji liniowej nakładana jest tzw. funkcja logistyczna, której wartości zawierają się w powyższym zakresie.
Przykładem funkcji logistycznej jest funkcja sigmoidalna:
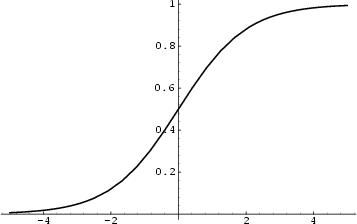
Jak widać na powyższym wykresie, jeśli wartość zwrócona przez funkcję liniową wynosi 0, funkcja sigmoidalna przekształca ją na wartość równą 0,5. Wartości ujemne odwzorowywane są przez funkcję sigmoidalną na liczby z przedziału od 0 do 0,5, natomiast dodatnie – na wartości zawarte w przedziale od 0,5 do 1. Wszystkie wartości funkcji sigmoidalnej zawierają się zatem w zakresie od 0 do 1. I o to chodzi!
Zakończenie
Regresja logistyczna jest jedną z podstawowych metod uczenia maszynowego. Stosowana jest ona między innymi w sieciach neuronowych, które dzięki nowym rozwiązaniom technologicznym (wyspecjalizowane karty graficzne, wydajne procesory tensorowe itp.) szturmem zdobywają kolejne bastiony ludzkiej inteligencji.
Ale o sieciach neuronowych będzie już mowa w innym wpisie na naszym blogu!
Autor:
prof. dr hab.
Krzysztof Jassem