W AI nie zawsze chodzi o stworzenie kolejnego modelu. Czasem największą wartość daje uporządkowanie danych, bez których trudno rzetelnie rozwijać i testować technologię.
Nasi doktoranci Iwona Christop i Maciej Czajka zaprezentowali na ICASSP 2026 w Barcelonie 🇪🇸 pracę „CAMEO: Collection of Multilingual Emotional Speech Corpora”.
ICASSP to jedna z najważniejszych konferencji na świecie w obszarze akustyki, mowy i przetwarzania sygnałów.
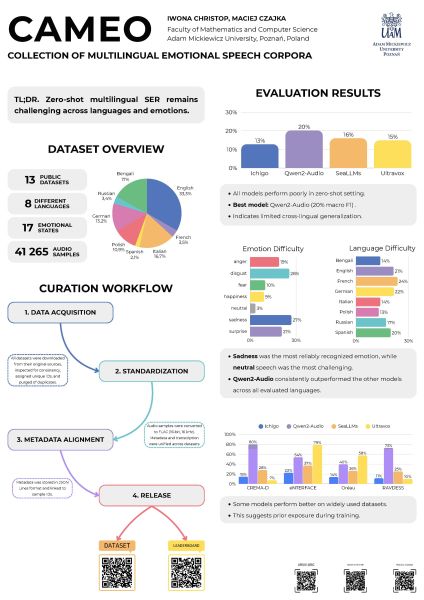
CAMEO obejmuje łącznie:
- 13 uporządkowanych publicznych datasetów mowy emocjonalnej,
- 8 języków,
- 41 265 próbek audio,
- prawie 42 godziny nagrań,
- 17 stanów emocjonalnych,
- transkrypcje oraz metadane dotyczące m.in. mówców, płci i wieku.
Problem jest prosty: dane do badań nad emocjami w mowie istnieją, ale są rozproszone, niespójne i trudne do porównywania.
CAMEO zbiera je w jednym miejscu, ujednolica formaty i metadane, a całość udostępnia na Hugging Face razem z leaderboardem.
To ważne dla rozwoju Speech Emotion Recognition, voice AI, asystentów głosowych, systemów call center czy generowania bardziej naturalnej mowy syntetycznej.
Jeden z ciekawszych wniosków?
Niektóre modele osiągały podejrzanie wysokie wyniki na wybranych datasetach, co może sugerować, że wcześniej były na nich uczone.
W praktycznym AI nie chodzi tylko o model. Chodzi o dane, kontekst i dobrze postawione pytanie.